Pulumi, A Beginner's Experience
Context
As part of a project to (over)engineer a system for Role-Based Access Control used for administrative tasks and back-office operations, I’ve decided to go with building reproducible and portable infrastructure leveraging infrastructure-as-code (IaC) tools.
I chose to use Pulumi as the IaC of choice over the well-known Terraform by HashiCorp in hopes to gain a deeper understanding of Pulumi after having first come into contact with it on a separate project months ago and having had a great impression of it.
Pulumi
How Pulumi works
Before diving further into this article, I would highly recommend having some understanding of Pulumi concepts like how Pulumi works and using Pulumi which are both well documented.
In summary, new resources are declared using Pulumi by running pulumi up which triggers the Pulumi engine to perform a check on the current state on the state backend, determine what resources needs to be modified, perform the necessary API calls to those providers to change the resource state and finally, update the state backend of this new state.
Pulumi Backend
To make things easier for state storing without reliance on Pulumi cloud (mainly for portability reasons), we’d decided to use S3 as our main Pulumi state backend.
The Design
A simplified view of the planned AWS Architecture Diagram:
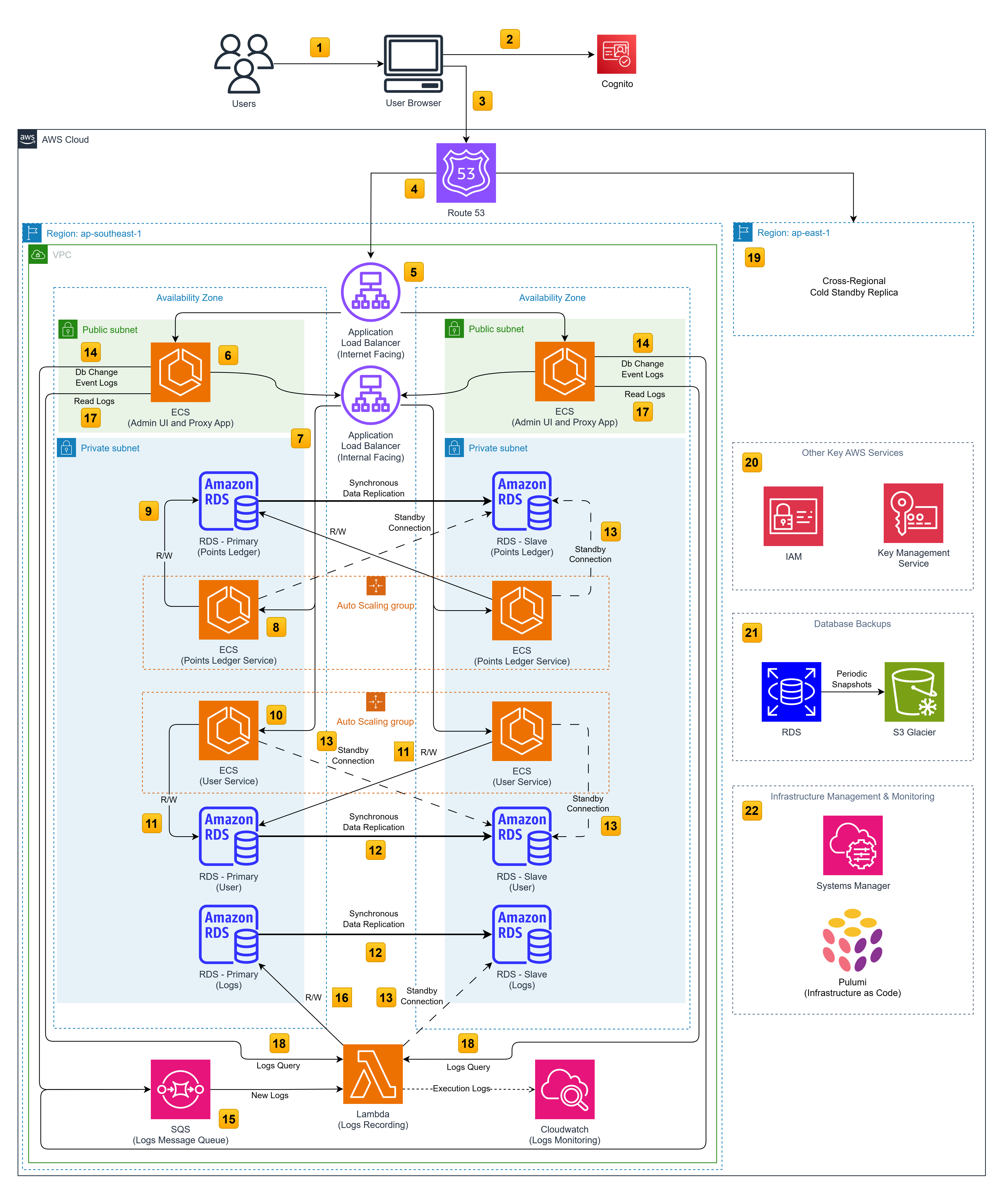
The above design uses the following services:
- Route53 to route traffic between a primary region and secondary replica region
- ALB to spread traffic between 2 availability zones within a particular region
- Another internal-facing ALB to spread traffic across replicas of downstream microservices
- ECS to orchestrate the containerized application on top of EC2 compute instances
- RDS as the main database service running Postgres@15
- Lambda for simple log recording tasks
- SQS to enable asynchronous log entries
- Various network configurations with VPCs, Subnets and Security Groups
Our goal is to sufficiently replicate services within the regional construct such that on the event that the secondary region is promoted to the primary, a tertiary region can be spun up and take over as the secondary region while the original primary region remains inactive for maintenance or other purposes.
Design Considerations
In order to establish services that can be easily ported over to multiple regions, we would ideally want to group configurations specific to regional services together and global services separately, following the Micro-Stacks Pulumi project organization pattern.
Here’s what we started with initially:
❯ tree pulumi -L 3pulumi/├── README.md├── global/│ ├── __main__.py│ ├── Pulumi.yaml│ ├── Pulumi.main.yaml│ └── requirements.txt├── database/│ ├── __main__.py│ ├── Pulumi.yaml│ ├── Pulumi.main.yaml│ └── requirements.txt├── primary/│ ├── __main__.py│ ├── Pulumi.yaml│ ├── Pulumi.main.yaml│ └── requirements.txt└── secondary/ ├── __main__.py ├── Pulumi.yaml ├── Pulumi.main.yaml └── requirements.txtThe original intention was to separate concerns for the primary and secondary regions apart from the global and database services. This is accomplished by leveraging Pulumi Projects for each of the global, database, primary and secondary specific infrastructure setups.
We quickly realized that it was silly to separate the primary and secondary regions as they largely contain the same configurations of the same types of services and it’ll just be repetitive to have a secondary on top of the already existing primary when we could have just used a different Pulumi stack within the a single project with differently defined parameters like the target AWS Region.
Another thing that was somewhat unnecessary was the separation of database and global since global was intended to be a shared configuration across AWS regions and the kind of configuration for RDS perfectly fits that in nature, even though it is technically a regional service.
We now end up with a project structure similar to the following:
❯ tree pulumi -d -L 3pulumi/├── global/│ ├── network/│ ├── rds/│ ├── route53/│ ├── __main__.py│ ├── Pulumi.yaml│ ├── Pulumi.main.yaml│ └── requirements.txt└── regional/ ├── ecs/ │ ├── service-A/ │ ├── service-B/ │ └── service-C/ ├── lb/ ├── network/ ├── serverless/ ├── __main__.py ├── Pulumi.yaml ├── Pulumi.sin.yaml ├── Pulumi.hkg.yaml └── requirements.txtWith the regional containing 2 stacks to stores the main configuration for the primary region in Singapore (./pulumi/regional/Pulumi.sin.yaml) and the secondary region in Hong Kong (./pulumi/regional/Pulumi.hkg.yaml).
❯ cat ./pulumi/regional/Pulumi.sin.yamlencryptionsalt: v1:xxxxxxconfig: aws:region: ap-southeast-1With an additional logical separation of related services like for ecs within the regional Pulumi
project.
A Deeper Look
‼️ NOTE: The various code snippets shown below are written by a beginner (unless labelled otherwise) and are meant to be references - use at your own risk!
Structure of Code
In the Global component of code, we define the key resources that are available and used actively across regions, and shouldn’t be modified frequently, such as the Route53 and various network related configurations.
❯ tree pulumi/global -L 2pulumi/global/├── Pulumi.dev.yaml├── Pulumi.yaml├── __main__.py├── network/│ └── __init__.py├── rds/│ └── __init__.py├── requirements.txt└── route53/ └── __init__.pyDefining network resources would look something like:
1import pulumi_aws as aws2import pulumi3
4config = pulumi.Config()5regions = config.require_object("regions")6
7if len(regions) != 2:8 raise Exception("This stack requires exactly two regions to be configured")9
10def create_vpc(cidr: str, region: str, provider: aws.Provider) -> aws.ec2.Vpc:11 return aws.ec2.Vpc(12 f"main-{region.replace('-', '_')}",13 cidr_block=cidr,14 enable_dns_hostnames=True,15 enable_dns_support=True,16 opts=pulumi.ResourceOptions(provider=provider),17 )18
19def create_subnet(20 vpc: aws.ec2.Vpc,21 cidr: str, # e.g. "10.0.0.8/24"22 az: str, # e.g. "ap-southeast-1a"23 provider: aws.Provider,24 is_public: bool = False,25) -> aws.ec2.Subnet:26 name = f"subnet-{az.replace('-', '_')}-{'public' if is_public else 'private'}"27 return aws.ec2.Subnet(28 name,29 vpc_id=vpc.id,30 cidr_block=cidr,31 availability_zone=az,32 map_public_ip_on_launch=is_public,33 opts=pulumi.ResourceOptions(provider=provider),34 )35
36def create_security_group(37 name: str,38 vpc: aws.ec2.Vpc,39 provider: aws.Provider,40) -> aws.ec2.SecurityGroup:41 return aws.ec2.SecurityGroup(42 name,43 vpc_id=vpc.id,44 ingress=[45 aws.ec2.SecurityGroupIngressArgs(46 protocol="-1",47 from_port=0,48 to_port=0,49 self=False,50 cidr_blocks=["0.0.0.0/0"],51 )52 ],53 egress=[54 aws.ec2.SecurityGroupEgressArgs(55 protocol="-1",56 from_port=0,57 to_port=0,58 cidr_blocks=["0.0.0.0/0"],59 )60 ],61 opts=pulumi.ResourceOptions(provider=provider),62 )63
64
65for region in regions:66 provider = aws.Provider(f"provider_{region}", region=region)67 vpc = create_vpc("10.0.0.0/16", region, provider)68 sg = create_security_group(f"ecs-security-group_{region}", vpc, provider)69 public_subnet_az_a = create_subnet(vpc, "10.0.1.0/24", f"{region}a", provider, True)70 private_subnet_az_a = create_subnet(vpc, "10.0.11.0/24", f"{region}a", provider)71 public_subnet_az_b = create_subnet(vpc, "10.0.2.0/24", f"{region}b", provider, True)72 private_subnet_az_b = create_subnet(vpc, "10.0.12.0/24", f"{region}b", provider)73 internet_gateway = aws.ec2.InternetGateway(74 f"internet-gateway_{region}",75 vpc_id=vpc.id,76 opts=pulumi.ResourceOptions(provider=provider),77 )78 route_table = aws.ec2.RouteTable(79 f"route-table_{region}",80 vpc_id=vpc.id,81 routes=[82 aws.ec2.RouteTableRouteArgs(83 cidr_block="0.0.0.0/0", gateway_id=internet_gateway.id84 )85 ],86 opts=pulumi.ResourceOptions(provider=provider),87 )88 public_subnet_route_table_association_az_a = aws.ec2.RouteTableAssociation(89 f"public_subnet_route_table_association_az_a_{region}",90 subnet_id=public_subnet_az_a.id,91 route_table_id=route_table.id,92 opts=pulumi.ResourceOptions(provider=provider),93 )94 public_subnet_route_table_association_az_b = aws.ec2.RouteTableAssociation(95 f"public_subnet_route_table_association_az_b_{region}",96 subnet_id=public_subnet_az_b.id,97 route_table_id=route_table.id,98 opts=pulumi.ResourceOptions(provider=provider),99 )100
101 pulumi.export(f"{region}:vpcId", vpc.id)102 pulumi.export(f"{region}:publicSubnetAzAId", public_subnet_az_a.id)103 pulumi.export(f"{region}:publicSubnetAzBId", public_subnet_az_b.id)104 pulumi.export(f"{region}:privateSubnetAzAId", private_subnet_az_a.id)105 pulumi.export(f"{region}:privateSubnetAzBId", private_subnet_az_b.id)106 pulumi.export(f"{region}:sgId", sg.id)Looking back, the code structure could definitely be a lot cleaner, but for a first time effort and built in favor for quick iteration, this was what we ended up with.
The main motivation of adopting such a structure is the logical hierarchy of the provisioned resources as it now becomes clear which subfolders is responsible for which resources on AWS.
Handling Secrets
Secrets sharing is a common workflow especially among team members. For this particular project, I find the use of the built-in secrets management (see also Managing Secrets with Pulumi | Pulumi Blog) to be more than sufficient for our use case.
For example, to define a shared database secret, all we need to do is define it in the stack configuration as a secret by running a command, which sets a configuration variable named dbPassword to the plaintext value verySecurePassword!:
❯ pulumi config set --secret dbPassword "verySecurePassword!"If we list the configuration for our stack, the plaintext value for dbPassword will not be printed:
❯ pulumi configKEY VALUEaws:region ap-southeast-1dbPassword [secret]Similarly, if the program attempts to print the value of dbPassword to the console - either intentionally or accidentally - Pulumi will mask it out:
1import pulumi2config = pulumi.Config()3print('Password: {}'.format(config.require('dbPassword')))Running this program yields the following result:
❯ pulumi upPassword: [secret]For further information on handling secrets, see the comprehensive Pulumi documentation on secrets.
A simple example of how this would look like in practical code would be:
1from network import NetworkResources, region_resources2import pulumi_aws as aws3import pulumi4
5config = pulumi.Config()6regions = config.require_object("regions")7retention_period = config.get_int("retentionPeriod") or 78
9db_user = config.require_secret("dbUser")10db_password = config.require_secret("dbPassword")11
12primary_provider = aws.Provider("primaryProvider", region=regions[0])13replica_provider = aws.Provider("replicaProvider", region=regions[1])14
15primary_region_resources: NetworkResources = list(16 filter(lambda r: r.region == regions[0], region_resources)17)[0]18
19secondary_region_resources: NetworkResources = list(20 filter(lambda r: r.region == regions[1], region_resources)21)[0]22
23# Create the primary RDS database instance.24primary_db_subnet_grp = aws.rds.SubnetGroup(25 "primary_db_subnet_grp",26 subnet_ids=[27 primary_region_resources.private_subnet_az_a.id,28 primary_region_resources.private_subnet_az_b.id,29 ],30 opts=pulumi.ResourceOptions(provider=primary_provider),31)32primary_db = aws.rds.Instance(33 "primary",34 allocated_storage=10,35 engine="postgres",36 engine_version="15",37 instance_class="db.t3.micro",38 username=db_user,39 password=db_password,40 backup_retention_period=retention_period,41 skip_final_snapshot=True,42 multi_az=True,43 vpc_security_group_ids=[primary_region_resources.sg.id],44 db_subnet_group_name=primary_db_subnet_grp.name,45 opts=pulumi.ResourceOptions(provider=primary_provider),46)47
48# Secondary read replica database in different region.49secondary_db_subnet_grp = aws.rds.SubnetGroup(50 "secondary_db_subnet_grp",51 subnet_ids=[52 secondary_region_resources.private_subnet_az_a.id,53 secondary_region_resources.private_subnet_az_b.id,54 ],55 opts=pulumi.ResourceOptions(provider=replica_provider),56)57
58secondary_db = aws.rds.Instance(59 "secondary",60 instance_class="db.t3.micro",61 replicate_source_db=primary_db.arn,62 backup_retention_period=retention_period,63 skip_final_snapshot=True,64 vpc_security_group_ids=[secondary_region_resources.sg.id],65 db_subnet_group_name=secondary_db_subnet_grp.name,66 opts=pulumi.ResourceOptions(provider=replica_provider),67)68
69pulumi.export("dbEndpointPrimary", primary_db.endpoint)70pulumi.export("dbEndpointSecondary", secondary_db.endpoint)71pulumi.export("dbPassword", db_password)72pulumi.export("dbUser", db_user)Putting It Together
When running the pulumi up command on a python stack, Pulumi will attempt to find and execute the entrypoint which is the __main__.py file. Hence that’s where necessary procedures of resource allocation should start.
We could also leverage the fact that python executes code on import modules and just import the necessary resources we want to provision.
1from network import *2from rds import *3from route53 import FailoverRecordTypeEnum, create_r53_record4import pulumi5
6def use_route53(nlb_id: str, failover_type: FailoverRecordTypeEnum):7 if nlb_id:8 create_r53_record(nlb_id, failover_type)9
10sin_stk = pulumi.StackReference(pulumi.Config().require("sinStack"))11sin_stk.get_output("nlb.id").apply(12 lambda x: use_route53(x, FailoverRecordTypeEnum.PRIMARY)13)14
15hkg_stk = pulumi.StackReference(pulumi.Config().require("hkgStack"))16hkg_stk.get_output("nlb.id").apply(17 lambda x: use_route53(x, FailoverRecordTypeEnum.SECONDARY)18)Referencing External Stacks
Following the Micro-Stack project structure, we have 2 stacks that requires references from the other, which could easily be resolved either by using an external configuration file as a reference or just simply using the Pulumi Output + StackReference.
1# source: https://www.pulumi.com/learn/building-with-pulumi/stack-references2import pulumi3
4config = pulumi.Config()5stack = pulumi.get_stack()6org = config.require("org")7
8stack_ref = pulumi.StackReference(f"{org}/my-first-app/{stack}")9
10pulumi.export("shopUrl", stack_ref.get_output("url"))In essence, this would allow the regional stack to get the output reference of global such as the VPC id to provision new resources to. An example of the implementation:
1import pulumi_aws as aws2import pulumi3
4config = pulumi.Config("aws")5region = config.require("region")6global_stk = pulumi.StackReference(pulumi.Config().require("globalStack"))7
8vpc_id: str = global_stk.require_output(f"{region}:vpcId")9sg_id: str = global_stk.require_output(f"{region}:sgId")10public_subnet_az_a_id: str = global_stk.require_output(f"{region}:publicSubnetAzAId")11public_subnet_az_b_id: str = global_stk.require_output(f"{region}:publicSubnetAzBId")12private_subnet_az_a_id: str = global_stk.require_output(f"{region}:privateSubnetAzAId")13private_subnet_az_b_id: str = global_stk.require_output(f"{region}:privateSubnetAzBId")14
15vpc = aws.ec2.Vpc.get(f"main-{region.replace('-', '_')}", id=vpc_id)16sg = aws.ec2.SecurityGroup.get(f"ecs-security-group_{region}", id=sg_id)17public_subnet_az_a = aws.ec2.Subnet.get(18 f"subnet-{region.replace('-', '_')}a-public",19 id=public_subnet_az_a_id,20)21private_subnet_az_a = aws.ec2.Subnet.get(22 f"subnet-{region.replace('-', '_')}a-private",23 id=private_subnet_az_a_id,24)25public_subnet_az_b = aws.ec2.Subnet.get(26 f"subnet-{region.replace('-', '_')}b-public",27 id=public_subnet_az_b_id,28)29private_subnet_az_b = aws.ec2.Subnet.get(30 f"subnet-{region.replace('-', '_')}b-private",31 id=private_subnet_az_b_id,32)33
34pulumi.export("aws:region", region)AWS Specific Details
Once we fully understood the core functionalities that Pulumi provides, what’s left is to understand the best practices for provisioning AWS resources, with or without IaC tools.
Resources:
- Security best practices for your VPC - Amazon Virtual Private Cloud
- Best practices - Amazon EC2 - Amazon Elastic Compute Cloud
- Best practices - Amazon ECS - Amazon Elastic Container Service
- Best practices - Networking - Amazon Elastic Container Service
- Best practices - AWS Lambda - AWS Lambda Functions
- Best practices - Amazon RDS - Amazon Relational Database Service
Challenges
Using Pulumi has mostly been pleasant, but it’s not without some hiccups once every so often.
Documentation
Disclaimer: Pulumi’s documentation in general is great - a lot better than many open-sourced tooling on the internet. However, from the eye of the novice, somethings are not as well described as I would hope for it to be.
I found that referencing Terraform’s documentation, coupled with AWS resource-specific guide, to be the best combination when working with new AWS resources to be provisioned through Pulumi.
Lack of References
Considering that Pulumi is a relatively young tool, researching for best practices to replicate was challenging due to the limited availability of resources and references compared to more established tools like Terraform or CloudFormation. When faced with issues foreign to me, it took me quite a while to search on places like stackoverflow or public GitHub repositories before finally finding solutions that are written for Terraform but yet still works in Pulumi (ironically this is another great thing about Pulumi since it uses the same APIs as Terraform does for infrastructure provisioning on cloud providers like AWS). Don’t even think about using Pulumi AI, using it has caused me more problems than if I were to just do a more in-depth research on the resource or just look at the Pulumi source code.
Pulumi has a relatively active slack channel where questions can be quickly answered but for a beginner, most of the time, the challenge lies in forming a good question, which coupled with lack of necessary context, can be quite time-consuming.
vs Terraform
The main reason why Terraform is used here as a comparison is because it has a lot of great features that are attractive to many: open-source, extensive documentation, and supports most major cloud providers and lower-level infrastructure system like Kubernetes.
However, Terraform isn’t without its challenges. The primary drawback lies in needing to learn and master the HashiCorp Configuration Language (HCL) in order to write resource configurations. While suitable for basic tasks, it becomes difficult to modularize code and articulate complex logical constructs such as if statements and for loops, particularly within expansive projects.
The Pulumi team has done a great job listing key areas of comparison between Pulumi and Terraform in their comparison documentation and at risk of repetition, I’ll be listing a few areas which impacted our ability get things out quick.
Popularity
Given that Terraform has been around for much longer, it definitely has a much larger community around it compared to Pulumi but I would say Pulumi’s community is growing fast and there are also much more activity on Pulumi’s GitHub repository than Terraform’s but Pulumi has about half the number of stargazers than Terraform.
This popularity affected the number of issues identified and shared among the community, which in turn directly impacted the availability of online resources that we could reference.
Concepts
Pulumi, similar to Terraform, support importing existing resources so that they can be managed. However, on top of that, Pulumi allows generation of code from an existing state but Terraform requires it to be manually written.
Pulumi also allows the conversion of templates by Terraform HCL, Kubernetes YAML, and Azure ARM into Pulumi programs, which is incredibly useful for teams that are already deep into the other IaC tools and want to convert to Pulumi.
Programming Language
Pulumi, in contrast to Terraform, enables users to leverage familiar general-purpose programming through their SDKs which supports multiple languages on different runtimes such as Python, Node.js (JavaScript, TypeScript), .NET (C#, F#, VB), Java, and even on YAML for configuration. This enables seamless integration with the user’s preferred IDE and allows users to leverage familiar code modularization designs and logical primitives directly through their preferred language and environment.
Final Thoughts
It’s worth a try.